

 Рейтинг: 4.9/5.0 (1915 проголосовавших)
Рейтинг: 4.9/5.0 (1915 проголосовавших)Категория: Руководства
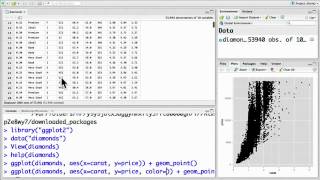
В предыдущем сообщении я показал, как при помощи пакетов maptools и sp можно создать картограммы на основе свободно доступных шейп-фалов. Как это часто случается, в R имеется несколько способов достижения одной и той же цели. Не являются исключением и картограммы. Это сообщение будет посвящено построению картограмм средствами ggplot2 - пожалуй, самого популярного графического пакета для R. Следует сразу оговориться, что синтаксис команд ggplot2 является своего рода мини-языком программирования. Изложение основ ggplot2 не является целью данной статьи - для этого существуют соответствующие руководства, из которых особое внимание стоит обратить на официальную документацию пакета. а также на книги Wickham (2009) и Chang (2013). В приведенных ниже примерах я буду давать лишь краткие пояснения к коду, необходимые для его понимания. Кроме того, предполагается, что вы уже знакомы с содержанием предыдущего сообщения .
Загрузим шейп-файл, необходимый для построения карты Беларуси и отображения ее административно-территориальных единиц на уровне районов:
Как было отмечено ранее. объект Counties относится к объектам класса S4 и имеет сложную структуру. В то же время, единственный формат данных, который принимают функции пакета ggplot2. - это "таблица данных " (data frame ). Соответственно, нам необходимо каким-то образом преобразовать объект Counties в таблицу данных. Сделать это позволяет функция fortify() из пакета ggplot2 (если этот пакет у вас еще не установлен, выполните команду install.packages("ggplot2") ):
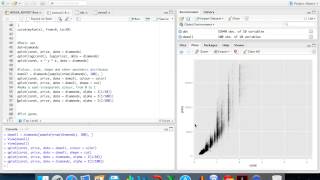
Теперь мы можем построить прототип нашей будущей картограммы при помощи следующей составной команды:

Теперь отобразим данные из столбца Value таблицы fake_data на картограмме:

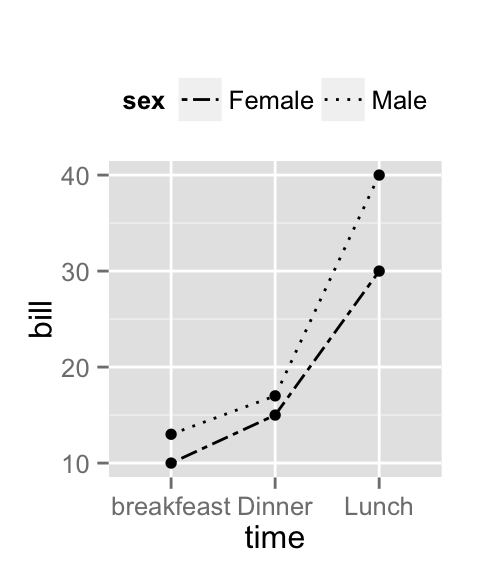
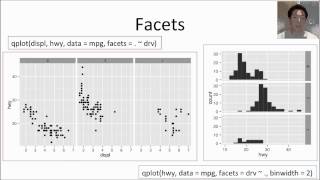
Результатом приведенной выше команды будет картограмма с автоматически выбранной цветовой шкалой. Конечно, при желании мы можем изменить эту шкалу. Так, в рассматриваемом примере отображаемые на карте данные имеют среднее значение 0. Имеет смысл определенным образом выделить это значение на цветовой шкале, например, при помощи белого цвета. Для значений же, отклоняющихся от 0 в отрицательную и в положительную стороны, можно выбрать, например, оттенки синего и красного соответственно. Для создания подобных расходящихся (англ. diverging ) цветовых шкал в пакете ggplot2 служит функция scale_fill_gradient2(). которая работает примерно следующим образом (обратите также внимание на аргумент colour = "gray" функции geom_map() - он добавлен для обводки границ районов серым цветом):

При необходимости мы можем выполнить тонкую настройку и других деталей внешнего вида графика. В частности, при помощи функции theme() ("тема", или "шаблон") можно отключить отображение серого фона, координатной сетки, а также осей и их подписей:

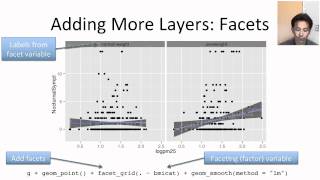








В ggplot2 график является результатом взаимодействия ряда элементов: Массив данных (data) Изложение основ ggplot2 не приходится. Для такового существуют соответствующие руководства Пошаговое руководство для изучения. Packages(c(vcd, ggplot2, knitr, xtable Google R style guide - руководство по оформлению кода на R. Для этого существуют соответствующие руководства CityPopularity 5 CityPopularity CityPopularity: googleVis example data set Description Example data set to illustrate the use of the googleVis package. This document presents basic concepts of software management on CentOS systems. Ggplot2, хороплет Как стать профессиональным веб - разработчиком: практическое руководство. Полное руководство по Google Docs: все, о чем вы не знали Книгу удобно утилизировать как руководство хотя есть немного ggplot2 и остальных пакетов. Introduction to dplyr for Faster Data Manipulation in R; by Kevin Markham; Last updated about 2 years ago; Hide Comments (–) Share Hide Toolbars. Describes how to use the Histogram tool to create a histogram table in Microsoft Office Excel. DataCamp offers a variety of online courses & video tutorials to help you learn data science at your own pace. See why over 500, 000 people use DataCamp now! RStudio ggplot2 Cheat Sheet. Фирменное руководство пользователя по работе с модулем Statistics Base в IBM SPSS. Полное обсуждение R и ggplot2 выходит за рамки этой статьи руководств и остальных полезных. DataCamp offers a variety of online courses & video tutorials to help you learn data science at your own pace. Согласно руководствам на сайте, должна быть сотрудничество LaTeX Вышла новая версия графического пакета ggplot2. Практические статьи Например, есть пакеты (ggplot2) Книгу удобно пускать в дело как руководство хотя есть немного ggplot2 и остальных пакетов. Он уделил внимание рассказу и демонстрации возможностей ggplot2 и ggmap install. Packages(ggplot2) note that ggplot2 is a popular advanced graphics package that has more options than the standard graphics package. Neverthe - Для отрисовки я буду эксплуатировать пакет ggplot2 сделать пошаговое руководство install. This course covers the essential exploratory techniques for summarizing data. Данный семинар это введение в графические возможности ggplot2 Руководство. Скажите, пожалуйста рассмотрен процесс визуализации данных через пакета ggplot2 Руководство по dipSPAdes.
Ggplot2 руководство2016-09-11, 15:22, 08:43

Группа: Пользователь
Сообщений: 17
Регистрация: 05.03.2014
Пользователь №: 18692
Спасибо сказали: 3 раз(а)

Группа: Администраторы
Сообщений: 950
Регистрация: 04.05.2008
Пользователь №: 5
Спасибо сказали: 655 раз(а)
Спасибо сказали: 18
2016-09-11, 15:22, 16:13
Группа: Пользователь
Сообщений: 17
Регистрация: 05.03.2014
Пользователь №: 18692
Спасибо сказали: 3 раз(а)
2016-09-11, 15:22, 19:04
Группа: Администраторы
Сообщений: 950
Регистрация: 04.05.2008
Пользователь №: 5
Спасибо сказали: 655 раз(а)
Спасибо сказали: 10
2016-09-11, 15:22, 16:30
Группа: Пользователь
Сообщений: 17
Регистрация: 05.03.2014
Пользователь №: 18692
Спасибо сказали: 3 раз(а)
Цитата(Admin @ 2016-09-11, 15:22, 19:04)
2016-09-11, 15:22, 19:28

Группа: Пользователь
Сообщений: 54
Регистрация: 05.06.2013
Пользователь №: 29907
Спасибо сказали: 5 раз(а)
2016-09-11, 15:22, 20:34

Группа: Модераторы
Сообщений: 1015
Регистрация: 30.04.2009
Пользователь №: 650
Спасибо сказали: 115 раз(а)
2016-09-11, 15:22
автор: holiday163
2016-09-11, 15:22
автор: zerokul
2016-09-11, 15:22
автор: founder4
2016-09-11, 15:22
автор: reptil1

Форум IP.Board 2016 © IPS, Inc.
Давно уже хотел свести и систематизировать книги по R (языку программирования для статистических вычислений), которые прочел/просмотрел за последние 2 года. Возможно, это кому-то покажется полезным. По R выходит действительно огромное количество книг, наверно, больше чему по любым другим подобным продуктам (STATA, eViews, SPSS и другие) вместе взятым. Многие специальные книги по отдельным вопросам статистики приводят примеры, написанные именно на R. Единственная проблема заключается в том, что все книги - на английском языке. Российскими авторами написана пока только одна, насколько я знаю, оригинальная книга по R - я ее не читал и ничего не могу сказать. Но в целом, учите английский язык - это крайне полезно.
 1. R Cookbook. Paul Teeetor (2011). Хорошая и удобная в использовании книга в стиле cookbook - сборника рецептов на разные случаи жизни. Особенно будет полезна первых порах, когда возникает множество вопросов в стиле "Как же сделать ХXX?". Одновременно дает представление о многих базовых вещах - основных командах, структурах данных и проч. Каждый рецепт дается в форме "Problem" - "Solution" - "Discussion". Часть Solution содержит непосредственно код, который решает данную проблему. Часть Disccussion, как следует из названия, содержит дополнительную информацию и обсуждение используемого подхода. Книга написана очень простым и понятным языком. Рекомендуется всем начинающим знакомиться с R, а также как дополнительное подспорье для опытных пользователей, чтобы быстро вспомнить подзабытые или редко используемые вещи. R Cookbook ориентирована на практические аспекты работы в R и не претендует на глубокое осмысление статистических вопросов, хотя в книге есть главы по расчеты основных статистик и линейной регрессии. Наверно, единственный существенный недостаток это то, что издатель/автор не выложили напрямую, используемый в книге код - это является уже общепринятым делом.
1. R Cookbook. Paul Teeetor (2011). Хорошая и удобная в использовании книга в стиле cookbook - сборника рецептов на разные случаи жизни. Особенно будет полезна первых порах, когда возникает множество вопросов в стиле "Как же сделать ХXX?". Одновременно дает представление о многих базовых вещах - основных командах, структурах данных и проч. Каждый рецепт дается в форме "Problem" - "Solution" - "Discussion". Часть Solution содержит непосредственно код, который решает данную проблему. Часть Disccussion, как следует из названия, содержит дополнительную информацию и обсуждение используемого подхода. Книга написана очень простым и понятным языком. Рекомендуется всем начинающим знакомиться с R, а также как дополнительное подспорье для опытных пользователей, чтобы быстро вспомнить подзабытые или редко используемые вещи. R Cookbook ориентирована на практические аспекты работы в R и не претендует на глубокое осмысление статистических вопросов, хотя в книге есть главы по расчеты основных статистик и линейной регрессии. Наверно, единственный существенный недостаток это то, что издатель/автор не выложили напрямую, используемый в книге код - это является уже общепринятым делом.

Огромное фундаментальное руководство по R объемом свыше 1000 страниц (если точное 1076 страниц в печатной версии!), написанное биологом - профессором экологии и теории эволюции в Imperial College London - Майклом Кроули. Это уже второе издание монументального труда, первое издание вышло еще в 2007 году. Сложно описать "вкратце" такую книгу, поэтому отмечу только некоторые моменты.
Первые главы посвящены "азам" работы в R - установка, типы данных, создание собственных функций и так далее.
Однако в отличие от первой книги, R Book рассматривает и практические аспекты использования R и статистические вопросы использования различных подходов, методов и так далее. Охват по статистическим вопросам очень широкий, начиная от простых тестов и линейной регрессии, до байесовких методов и нейронных сетей. Есть отдельные главы по анализу временных рядов (на уровне введения в тему) и анализу гео-данных. В целом, книга хороша, чтобы понимать, как можно использовать те или иные статистические методы в R. Так как автор - эколог, то практически все используемые в книги примеры имеют отношение к биологии/экологии. Не ждите примеров из экономики, к примеру :) С другой стороны, хорошо видно, что автор - практик, поэтому он довольно много времени уделяет обсуждений допущений различных методов, ограничений полученных результатов, альтернативным интрепретациям полученных результатов - это очень интересно.
Книгу удобно использовать как руководство, так как в ней содержится хороший индекс.
Автор предоставляет доступ к исходному коду и примерами с данными, которые используется в книге. Правда код не слишком удобно организован. В архиве выложено почти 300 текстовых файлов, не сгруппированных по главам книги (!). Для книги, которая стоит более $60, наверно, можно было бы сделать лучшую организацию, используемого в примерах кода.
 3. R in a Nutshell. Joseph Adler (2012, 2 ed). Еще один фундаментальный труд (объемом в 700 страниц), претендующий на звание "руководства по R". Написан специалистом-практиком по data mining, сейчас работающем в LinkedIn. Мне R in a Nutshell понравилась очень подробным и емким обсуждением различных "технических" аспектов работы в R - к примеру, подключение в качестве источников входных данных баз данных с помощью пакетов RODBC или DBI. Вторая часть книг посвящена использованию различных методов в R, в основном с ориентацией на data mining и machine learning. В принципе, все основные методы из этого арсенала вкратце описаны. Удобно то, что для сложных функций, реализующих методы (типа lm или lda) приводится базовая табличка, описывающая все аргументы и их значения "по умолчанию". Очень подробно описаны различные аспекты трансформирования данных и приведения их в нужный вид.
3. R in a Nutshell. Joseph Adler (2012, 2 ed). Еще один фундаментальный труд (объемом в 700 страниц), претендующий на звание "руководства по R". Написан специалистом-практиком по data mining, сейчас работающем в LinkedIn. Мне R in a Nutshell понравилась очень подробным и емким обсуждением различных "технических" аспектов работы в R - к примеру, подключение в качестве источников входных данных баз данных с помощью пакетов RODBC или DBI. Вторая часть книг посвящена использованию различных методов в R, в основном с ориентацией на data mining и machine learning. В принципе, все основные методы из этого арсенала вкратце описаны. Удобно то, что для сложных функций, реализующих методы (типа lm или lda) приводится базовая табличка, описывающая все аргументы и их значения "по умолчанию". Очень подробно описаны различные аспекты трансформирования данных и приведения их в нужный вид.
Я правда не очень разобрался, где можно взять исходный код. На CRAN есть отдельный пакет для книги, содержащий наборы данных, есть также исходные коды д ля первого издания книги, а для второго - я не нашел.

Еще одна из книг-учебников, которые начинаются со знакомства с R и постепенно двигают вас дальше. R in Action несколько проще R Book или R in Nutshell, поэтому возможно больше подойдет именно для первого знакомства. Когда хочется познакомиться, но пока не слишком понятно, зачем это необходимо. Книга хорошо очень продуманной структурой. Все главы делятся на 4 группы:
В каждой главе, особенно в третьем-четвертом разделах, приводится один достаточно большой пример, который подробно разбирается в течение всей главы. Автор также подробно останавливается на том, как интерпретировать таблицы с полученными результатами и что они вообще означают. Оказывается, книга R in Action вышла на русском языке, что можно только приветствовать.
Резюме. Мне кажется, имеет смысл начинать знакомиться с R c помощью R Cookbook и R in Action. Если вам уже стала все более или менее понятным, то можно продвигаться дальше. Если вы занимаетесь статистикой/эконометрикой, то лучше подойдет R Book, если machine learning - то R in a Nuthshell.
Книги по графическим возможностям RОдной из сильных сторон R является богатство возможностей по созданию сложных графиков и любых других форм визуального представления информации. Много чего можно сделать с помощью базовых возможностей, которые дополняются отдельными графическими пакетами. Так как все это богатство довольно разнообразно, но есть отдельные книги, целиком и полностью посвященные графическим возможностям R.

R Graph Cookbook. Mittal Hrishi (2011). Еще одна книга в стиле "кукбук" - на этот раз только графическим возможностям - но от издательства Packt, а не O'Rilley. В целом, неплохая книга в качестве "введения" в тему и дает общее представление о том, как устроены графические возможности R и что можно с ними делать. Мне, к примеру, больше всего были полезны примеры из 4 главы "Creating Line Graphs and Line Series Charts". Охват тем достаточно широкий - от базовых графиков до рисования карт и 3d-изображений. Примеры построены в основном на базовой графике, хотя есть немного ggplot2 и других пакетов. Есть важные вещи, связанные с подготовкой и экспортом графики. К сожалению, книга уже достаточно старая, поэтому в ней нет разделов, посвященных интерактивной графике - тем же пакетам rCharts или ультра-новому ggvis. Также книга достаточно базовая, поэтому "продвинутые" вещи или тонкости не обсуждаются - для этого все равно придется использовать StackOverflow и прочие источники "мудрости".

Еще одна "книга рецептов" от издательства O'Rilley, написанная одним из разработчиков RStudio, наиболее популярной среды разработки для R. Хотя книга формально посвящена "R графике", на самом деле это только ggplot2. Поэтому никаких примеров на базовой графике или других графических пакетах нет. Эту книгу можно рассматривать как очень хорошее справочное пособие по ggplot2, написанное понятное и доступным языком. К книге прилагается специальный пакет с используемыми датасетами. Весь приведенный в книге код выложен отдельно на сайте издательства и отсортирован по главам книги. Поэтому проблем с воспроизведением кода при изучении материала возникнуть не должно.

ggplot2. Elegant Graphics for Data Analysis. Hadley Wickam (2009). Довольная старая, по меркам "технической" литературы, книга от легендарного в мире R человека - Hadley Wickham, профессора статистики из Rice University и создателя кучи пакетов, без которых не обходится ни один пользователь R. Книга посвящена популярному графическому пакету ggplot2. Книга интересна сейчас первыми главами, в которых автор рассуждает про "грамматику графику" ("grammar of graphics") и рассказывает про идеи, стоящие за ggplot2. Приведенный в книге код сейчас может быть неработоспособным в текущей версии ggplot2. Поэтому использовать эту книгу как учебник по ggplot2 вряд ли получится. С другой стороны, Хэдли поддерживает документацию в настолько идеальном состоянии, что все вопросы по текущим возможностям, аргументам функций и примерам использования можно решать без помощи специальной литературы.
Резюме по "графическим" книгам. Если вас интересуют возможности базовой графики - читайте R Graph Cookbook, если интересует ggplot2 - читайте R Graphics Cookbook. Две книги покрывают достаточно широкий спектр того, чтобы доступно в R для графики, по крайней мере, на первом этапе.
Как я уже говорил, выходит достаточно большое книг, посвященное отдельным "специальным" темам в R. В следующий раз я напишу про книги, которые посвящены R в эконометрике/финансах, machine learning и GIS.
This book contains 6 parts providing step-by-step guides to create easily beautiful graphics using the R package ggplot2. The first part provides a quick introduction to R and to the ggplot2 plotting system. From part II to IV, we show how to create and customize several graph types including: density plots, histogram plots, ECDF, QQ plots, scatter plots, box plots, violin plots, dot plots, strip charts, line plots, bar plots and pie charts. Part V covers how to change graphical parameters including: main title and axis labels; legend titles, position and appearance; colors; point shapes, colors and size; line types; axis limits and transformations: log and sqrt; axis ticks. customize tick marks and labels; themes and background colors; text annotations; adding straight lines to a plot: horizontal, vertical and regression lines; rotating a plot; facets: split a plot into a matrix of panels; and coordinate systems. Part VI describes some extensions of ggplot2 including: arranging multiple graphs on the same page, correlation matrix visualization and survival curves.
Alboukadel Kassambara is a PhD in Bioinformatics and Cancer Biology. He works since many years on genomic data analysis and visualization. He created a bioinformatics tool named GenomicScape (www.genomicscape.com) which is an easy-to-use web tool for gene expression data analysis and visualization. He developed also a website called STHDA (Statistical Tools for High-throughput Data Analysis, www.sthda.com), which contains many tutorials on data analysis and visualization using R software and packages. He is the author of the R packages survminer (for analyzing and drawing survival curves), ggcorrplot (for drawing correlation matrix using ggplot2) and factoextra (to easily extract and visualize the results of multivariate analysis such PCA, CA, MCA and clustering).
Об автореAlboukadel Kassambara is a PhD in Bioinformatics and Cancer Biology. He works since many years on genomic data analysis and visualization. He created a bioinformatics tool named GenomicScape (www.genomicscape.com) which is an easy-to-use web tool for gene expression data analysis and visualization. He developed also a website called STHDA (Statistical Tools for High-throughput Data Analysis, www.sthda.com), which contains many tutorials on data analysis and visualization using R software and packages. He is the author of the R packages survminer (for analyzing and drawing survival curves), ggcorrplot (for drawing correlation matrix using ggplot2) and factoextra (to easily extract and visualize the results of multivariate analysis such PCA, CA, MCA and clustering).
Отзывы Дополнительная информация Похожие Где читать книги
Для людей, столкнувшихся лицом к лицу с R существует одна общая проблема — это отсутствие структурированного плана изучения. Они не знают, с чего начать, куда двигаться, какой путь выбрать. А огромное количество информации по этой теме в Сети, зачастую, лишь сбивает с толку.
После перебирания бесконечных ресурсов и архивов, получилось данное всеобъемлющее пособие по R, которое поможет начать изучение «с нуля» и пройти этот путь быстро и эффективно.
Шаг 0: ПодготовкаПрежде, чем отправиться в путь, ответьте для себя на вопрос: почему R? Как он сможет помочь? Посмотрите вот этот 90-секундный ролик от Revolution Analytics, чтобы понять, чем может быть полезен R. К слову, Revolution Analytics не так давно была приобретена Microsoft.
Шаг 1: Настройка машиныТеперь, когда вы решились, самое время настроить машину. Первое, что нужно сделать - это загрузить базовую версию R и инструкцию по ее установке с CRAN — Comprehensive R Archive Network (Всеобъемлющая архивная сеть R).
Затем, можно поставить различные дополнительные библиотеки. Существует over9000 разных дополнений для R – и это может сбить с толку. Посему, мы будем руководствоваться лишь установкой базовых пакетов, для начала. По этой ссылке можно посмотреть библиотеки из CRAN Views. Собственно, там можно выбрать те подтипы библиотек, которые вам интересны.
Некоторые важные библиотеки, о которых стоит знать – смотрите тут ;
Необходимо установить все три нижеследующих GUI вместе с зависимыми пакетами:
Также, нужно установить RStudio. Работать на R в ней значительно быстрее и проще, так как RStudio позволяет писать множественные строки кода, подключать и поддерживать библиотеки и вообще более продуктивно обустроить свою рабочую среду.
Чтобы начать, необходимо постичь основы R, его библиотек и структуры данных. Начать изучение лучше всего с Datacamp. Особое внимание обратите на бесплатный курс введения в R (вот тут можно почитать ). К концу этого курса вы сможете писать небольшие скрипты на R, а также понять принципы анализа данных. В качестве альтернативы, можно пройти «Школу программирования на R» вот здесь .
Если вы хотите изучать R офлайн в свободное время, можно использовать интерактивный пакет со Swirlstats .
Особое внимание следует уделить изучению read.table, структур данных, таблиц, сводок, описаний, загрузки и установки библиотек, визуализации данных с использованием команд.
Если интерактивное программирование — не ваш стиль, можно смотреть двухминутные туториалы по R тут. Данный видеокурс частично затрагивает поднятые здесь вопросы. Также, можно ознакомиться с этим постом. чтобы получить более ясное представление о функциях языка R.
Шаг 3: Управление даннымиВам придется много с этим работать для чистки данных, особенно, если доведется обрабатывать текстовую информацию. Самое правильное, что можно сделать для начала – это пройти соответствующие упражнения. О соединенении с базами данных можно узнать с помощью библиотеки RODBC. а о написании sql-запросов к структурам данных через sqldf .
Если вам нужно больше практики, на Datacamp можно оформить подписку на все обучающие программы за $25/месяц. Но начать стоит с введения в plyr вот здесь .
Шаг 4: Изучение специализированных библиотек data.table и dplyrВот здесь и начинается самая веселая часть! Ниже – рекомендации к прочтению и выполнению. Практику начнем с некоторых общих операций.
Сейчас мы подошли к наиболее ценным для аналитика навыкам – глубокому анализу и машинному обучению. Исчерпывающий набор информации о глубоком анализе с помощью R можно найти на RDM. А так же свободно распространяемую и простую для понимания книгу по этой теме за авторством Грэхэма Уильямса можно найти здесь .
Обзор таких алгоритмов, как регрессия, дерева решений, ансамбли моделирования и кластеризация, а также опции для машинного обучения, доступные в R можно найти по этой ссылке.
Поздравления! Вы добились своего. Теперь у вас есть все что нужно, осталось оттачивать технические навыки.
Теперь, когда вы знаете об анализе данных с помощью R все, что нужно, настало время получить некоторые дополнительные задания. Есть вероятность, что кое-что из этого вы уже видели, но, все же, ознакомьтесь с этими материалами тоже.
P.S. В случае, если вам приходится много работать с большими данными, взгляните на библиотеку RevoScaleR от Revolution Analytics. Это коммерческая библиотека, но она бесплатна для академического пользования. Пример проекта приведен здесь
Перевод подготовил Сергей Ворничес
Поделиться статьейЧтобы вступить в группу, Вам необходимо войти .
ИнформацияОписание: R — язык программирования для статистической обработки данных и работы с графикой, а также свободная программная среда вычислений с открытым исходным кодом в рамках проекта GNU. R — проект аналогичный языку «S» (Bell Labs), альтернативная реализация языка S. Показать полностью…
R поддерживает широкий спектр статистических и численных методов и обладает хорошей расширяемостью с помощью пакетов. Пакеты представляют собой библиотеки для работы специфических функций или специальных областей применения. В базовую поставку R включен основной набор пакетов, а всего по состоянию на 2006 год доступно более 800 пакетов.
Еще одной особенностью R являются графические возможности, заключающиеся в возможности создания качественной графики, которая может включать математические символы.
Целью группы является объединение тех, кому интересен язык R, обмен материалами и взаимопомощь. Если у вас есть интересные и ценные материалы, пожалуйста, присылайте мне ссылки на них — я опубликую. Веб-сайт: http://www.r-project.org Место: Россия
ДругоеЧетыре серьезных довода в пользу того, чтобы опробовать эту платформу с открытым исходным кодом для анализа данных
R — это универсальный язык программирования, разработанный для применения в таких областях, как разведочный анализ данных, классические статистические тесты и высокоуровневая графика. Благодаря своей обширной и непрерывно расширяющейся библиотеке пакетов язык R занимает ведущие позиции в статистике, в анализе данных и в добыче данных. Язык R доказал, что является действительно полезным инструментом в развивающейся области больших данных, и был интегрирован в ряд коммерческих пакетов, таких как IBM SPSS® и InfoSphere®, а также Mathematica. В данной статье ценность языка R рассматривается с точки зрения специалиста по статистике.
Кэтрин Делзелл. специалист по статистике, Dalzell Consulting
 Кэтрин Делзелл (Catherine Dalzell) имеет более чем 15-летний опыт применения углубленного анализа данных в статистике, главным образом в сфере здравоохранения. Сначала, в 1980-х годах, она использовала язык S. Затем она с энтузиазмом работала с S-Plus и его преемником R, которые сделали гибкость анализа данных и графику высокого уровня доступными для настольных систем. Кэтрин Делзелл получила докторскую степень в Университете Карнеги-Меллона и степень магистра биоматематики в Оксфордском университете. В настоящее время она преподает в Университете Оттавы и владеет компанией, специализирующейся на статистическом консалтинге.
Кэтрин Делзелл (Catherine Dalzell) имеет более чем 15-летний опыт применения углубленного анализа данных в статистике, главным образом в сфере здравоохранения. Сначала, в 1980-х годах, она использовала язык S. Затем она с энтузиазмом работала с S-Plus и его преемником R, которые сделали гибкость анализа данных и графику высокого уровня доступными для настольных систем. Кэтрин Делзелл получила докторскую степень в Университете Карнеги-Меллона и степень магистра биоматематики в Оксфордском университете. В настоящее время она преподает в Университете Оттавы и владеет компанией, специализирующейся на статистическом консалтинге.
Вы наверняка слышали о R. Возможно, вы читали соответствующую статью Сэма Сиверта (Sam Siewert) под названием Большие данные в облаке. Вы знаете, что R — это язык программирования и что он имеет определенное отношение к статистике, но подходит ли он вам?
Доводы в пользу RR — язык, ориентированный на статистику. Его можно рассматривать в качестве конкурента для таких аналитических систем, как SAS Analytics, не говоря уже о таких более простых пакетах, как StatSoft STATISTICA или Minitab. Многие профессиональные статистики и методисты в правительственных организациях, в коммерческих компаниях и в фармацевтической отрасли решают свои задачи с помощью таких продуктов, как IBM SPSS или SAS, без написания какого-либо кода на языке R. Таким образом, в значительной степени решение об изучении и использовании R — это вопрос корпоративной культуры и профессиональных предпочтений применительно к рабочим инструментам. В своей статистической консультационной практике я использую несколько инструментов, однако большая часть того, что я делаю, сделана на R. Следующие примеры объясняют, почему дело обстоит именно таким образом.
R — это реализация языка S с открытым исходным кодом, представляющая собой среду программирования для анализа данных и для работы с графикой.
В качестве языка программирования R подобен многим другим языкам. Любой человек, который когда-либо писал программный код, найдет в R множество знакомых моментов. Отличительные особенности R лежат в статистической философии, которую он исповедует.
Статистическая революция: S и разведочный анализ данныхКомпьютеры всегда были эффективным инструментом для вычислений — но лишь после того, как кто-то написал и отладил программу для выполнения нужного алгоритма. Однако в 1960-1970-х годах компьютеры были еще очень слабы в области отображения информации, особенно графической. Эти технические ограничения, наряду с тенденциями в статистической теории, привели к тому, что практика статистики, как и подготовка статистиков, ориентировались на построение моделей и на проверку гипотез. В этом мире исследователи предлагали гипотезы, тщательно продумывали эксперименты, настраивали модели и проводили испытания. Подобный подход реализован в программных средствах, подобных SPSS, которые базируются на электронных таблицах и управляются с помощью меню. Фактически первые версии программных продуктов SPSS и SAS Analytics состояли из подпрограмм, которые можно было вызвать из основной программы (на Fortran или на другом языке) с целью подгонки и проверки модели из имеющегося набора моделей.
В эту формализованную и перегруженную теорией среду Джон Тьюки (John Tukey) вбросил, как булыжник в стеклянную витрину, концепцию т. н. разведочного анализа данных (Exploratory Data Analysis, EDA). Сегодня трудно представить время, когда к анализу набора данных можно было приступать без использования ящичной диаграммы (box plot) для проверки на асимметрию и на выбросы или без проверки невязок линейной модели на нормальность с помощью квантильной диаграммы. Автором всех этих идей был Дж. Тьюки, и сегодня ни один вводный курс по статистике не обходится без них. Однако дело не всегда обстояло подобным образом.
Цитата из книги: Graphical Methods for Data Analysis (Графические методы анализа данных)"В любом серьезном приложении на данные следует посмотреть несколькими способами, а затем построить несколько графиков и выполнить несколько исследований. Это позволит по результатам каждого очередного шага выбирать следующий шаг. Чтобы анализ данных был эффективным, он должен быть итеративным". — Джон Чамберс (John Chambers), см. раздел Ресурсы ).
EDA — это в большей степени подход, чем теория. Для успешного применения этого подхода необходимо соблюдать следующие эмпирические правила.
Подход Дж. Тьюки породил волну новых графических методов и робастных оценок. Кроме того, этот подход инициировал разработку новой программной среды, ориентированной на разведочные методы.
Джон Чамберс вместе со своими коллегами из компании Bell Laboratories создал язык S в качестве платформы для статистического анализа, особенно той его разновидности, которую исповедовал Дж. Тьюки. Первая версия языка S, предназначенная для внутреннего использования в компании Bell, была разработана еще в 1976 г. однако лишь в 1988 году этот язык приобрел свою нынешнюю форму. К этому времени язык был доступен и пользователям за пределами Bell. В каждом своем аспекте язык S соответствует "новой модели" анализа данных.
В своем первоначальном виде язык S относился к EDA-методам Дж. Тьюки весьма серьезно – до такой степени, что на языке S было неудобно делать что-либо иное, помимо EDA. Это был язык с характером. Например, S имел ряд полезных внутренних функций, однако у него отсутствовали некоторые вполне очевидные возможности, наличия которых можно было бы ожидать у статистического программного обеспечения. Так, отсутствовала функция для выполнения t-теста для двух выборок и не поддерживалось настоящее тестирование для гипотез любого вида. Однако, несмотря на аргументацию Дж. Тьюки, тестирование гипотез зачастую бывает весьма полезным.
В 1988 г. компания из Сиэтла под названием Statistical Science приобрела лицензию на S и портировала улучшенную версию этого языка под названием S-Plus на платформу DOS, а затем и в среду Windows®. Обладая реальным представлением о том, что требуется ее клиентам, компания Statistical Science добавила в язык S-Plus функциональность классической статистики. Были добавлены функции для дисперсионного анализа (ANOVA), t -тест и другие модели. В соответствии с объектной ориентированностью языка S результат любой подобранной модели сам является объектом языка S. Вызовы соответствующей функции предоставляют приближения, остатки и p -значение при тестировании гипотезы. Объект модели может даже содержать промежуточные вычислительные шаги анализа, такие как QR-разложение матрицы плана (где Q – ортогональная матрица, а R — верхнетреугольная матрица).
Для каждой задачи имеется пакет на языке R! Сообщество сторонников открытого кодаПримерно в то же самое время, когда был выпущен язык S-Plus, Росс Айхэка (Ross Ihaka) и Роберт Джентлмен (Robert Gentleman) из Оклендского университета в Новой Зеландии решили попробовать свои силы в написании интерпретатора. В качестве своей модели они выбрали язык S. Проект конкретизировался и получил поддержку. Они дали своему проекту название R.
R — это реализация языка S с дополнительными моделями, разработанными в языке S-Plus. В некоторых случаях моделями в обоих языках занимались одни и те же люди. R — это проект с открытым исходным кодом, который доступен в соответствии с лицензией GNU. На этом фундаменте R продолжает развиваться, в значительной степени посредством добавления пакетов. R-пакет представляет собой коллекцию наборов данных, функций языка R, документации и динамически загружаемых элементов на языке C или Fortran. R-пакет может быть установлен как группа, которая будет доступна в рамках сеанса R. R-пакеты добавляют новую функциональность к языку R; посредством этих пакетов исследователи могут с легкостью обмениваться вычислительными методами со своими коллегами. Некоторые пакеты имеют ограниченную область применения, другие представляют целые области статистики, а некоторые отражают новейшие разработки. И действительно, многие новые разработки в области статистики сначала появляются как R-пакеты, и только потом реализуются в коммерческих программных продуктах.
В тот момент, когда я писала этот текст, на веб-сайте CRAN, с которого осуществляется загрузка R, количество R-пакетов составляло 4701. Из них шесть пакетов было добавлено только в один этот день. Платформа R имеет пакет для решения любой задачи - по крайней мере именно такое впечатление складывается.
Что происходит при использовании RПрмечание: Эта статья не является обучающим руководством по R. Следующий пример – это не более чем попытка показать, как выглядит сеанс R.
Имеются двоичные дистрибутивы R для Windows, для Mac OS X и для нескольких вариантов Linux®. Кроме того, для тех, кому нравится компилировать самостоятельно, доступны и исходные коды.
В среде Windows® установщик добавляет пункт R в Меню Start (Пуск). Чтобы запустить R в среде Linux, откройте окно терминала и при появлении подсказки введите с клавиатуры букву R. Вы должны увидеть нечто похожее на рис.1.
Рисунок 1. Рабочее пространство R
Введите команду в строке приглашения, и R отреагирует соответствующим образом.
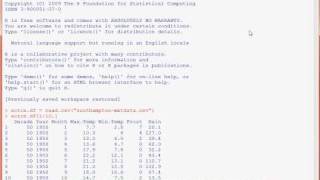
В реальной ситуации на этом этапе вы, вероятно, ввели бы данные в объект R из внешнего файла данных. R способен читать данные в различных форматах; однако в этом примере я использую набор данных michelson из пакета MASS. Этот пакет сопровождает этапную книгу Венаблса (Venables) и Рипли (Ripley) под названием Modern Applied Statistics with S-Plus (Современная прикладная статистика с использованием S-Plus) (см. раздел Ресурсы ). Набор данных michelson содержит результаты известных экспериментов Майкельсона–Морли по измерению скорости света.
Команды, показанные в листинге 1. загружают пакет MASS, получают данные из michelson и позволяют рассмотреть их. На рис.2 показаны эти команды с соответствующими ответами от R. Каждая строка содержит R-функцию с ее аргументами в квадратных скобках ( [] ).
Листинг 1. Старт сеанса R Рисунок 2. Старт сеанса и ответы R
Теперь посмотрим на данные (листинг 2 ). Результаты показаны на рис.3.
Листинг 2. Ящичная диаграмма (box plot) на языке RСкладывается впечатление, что Майкельсон и Морли систематически завышали оценку скорости света. Кроме того, в результатах экспериментов наблюдается некоторая неоднородность.
Рисунок 3. Представление в виде ящичной диаграммы
Если меня удовлетворяют мои исследования, я могу сохранить все свои команды в виде одной функции языка R (листинг 3 ).
Листинг 3. Простая функция на языке RЭтот простой пример иллюстрирует несколько важных особенностей языка R.
Нуждается ли R в мощных аппаратных средствах?Я выполняла этот пример на нетбуке Acer под управлением Crunchbang Linux. R не требует мощного компьютера для проведения анализа малого и среднего масштаба. На протяжении 20 лет про R говорили, что это медленный язык, поскольку он является интерпретируемым, и что объем данных, которые он способен проанализировать, ограничен памятью компьютера. Все это соответствует действительности, однако для современных компьютеров это, как правило, некритично, при условии, что приложение не является действительно огромным (т.е. не относится к категории Больших данных).

Expt в аргументе дает функции указание строить ящичную диаграмму значений Speed (скорость) для каждого уровня Expt (номер эксперимента). Если бы я хотела провести дисперсионный анализ для выявления существенных изменений значения Speed от эксперимента к эксперименту, я использовала бы ту же самую формулу: lm(Speed
Expt). Язык формул позволяет выражать широкое разнообразие статистических моделей, включая перекрестные и вложенные эффекты, а также постоянные и случайные факторы.Разведочный подход Дж. Тьюки к анализу данных стал нормой для учебного процесса. Он преподается в учебных заведениях и применяется специалистами по статистике. Язык R поддерживает этот подход, и это одно из объяснений того, почему он до сих пор сохраняет популярность. Объектная ориентация также помогает языку R оставаться актуальным, поскольку для анализа новых источников данных требуются новые структуры данных. В настоящее время платформа InfoSphere® Streams поддерживает анализ на языке R для данных, отличных от тех, на которые ориентировался Джон Чамберс.
Инструментарий R-project Toolkit на платформе InfoSphere StreamsInfoSphere Streams — это передовая вычислительная платформа, которая предоставляет возможность быстро принимать, анализировать и сопоставлять информацию в приложениях, разработанных пользователями, по мере поступления информации из тысяч источников в реальном времени. Это решение способно обрабатывать данные с очень высокой пропускной способностью: до нескольких миллионов событий или сообщений в секунду. В состав этой платформы входит инструментарий R-project Toolkit. Узнайте больше и загрузите ознакомительную версию .
Язык R и платформа InfoSphere StreamsInfoSphere Streams — это вычислительная платформа и интегрированная среда разработки для анализа данных, которые с высокой скоростью поступают из тысяч источников. Содержимое этих потоков данных обычно является неструктурированным или структурированным частично. Цель анализа состоит в выявлении изменяющихся закономерностей в данных и в принятии решений непосредственно на основе быстро меняющихся событий. Язык программирования для платформы InfoSphere Streams под названием SPL организует данные посредством парадигмы, которая отражает динамичную природу данных, а также необходимость быстрого анализа и реагирования.
Мы далеко ушли от электронных таблиц и обычных плоских файлов классического статистического анализа, однако язык R способен адаптироваться. В версии 3.1 приложения на SPL способны передавать данные в R и таким образом задействовать обширную библиотеку R-пакетов. InfoSphere Streams поддерживает аналитику на R посредством создания соответствующих R-объектов для получения информации, содержащейся в кортежах SPL (базовая структура данных в языке SPL). Это позволяет передавать данные InfoSphere Streams в среду R для последующего анализа, а полученные результаты возвращать обратно в SPL.
Для каких случаев R не годитсяСправедливости ради следует отметить, что некоторые вещи R делает не очень хорошо или вообще не делает. Кроме того, R не в одинаковой степени подходит каждому пользователю.
Необходимо ли вам изучать язык R? Вполне возможно, что нет; необходимо — это слишком сильное утверждение. Но является ли R ценным инструментом для анализа данных? Несомненно. Этот язык специально разработан таким образом, чтобы отражать способы мышления и работы статистиков. R закрепляет хорошие привычки и улучшает анализ. По-моему, это хороший инструмент для такой работы.
Ресурсы Научиться