






 Рейтинг: 4.1/5.0 (1826 проголосовавших)
Рейтинг: 4.1/5.0 (1826 проголосовавших)Категория: Руководства
Библиотека сайта или "Мой Linux Documentation Project"
Шесть лучших программ для Data Mining с открытым исходным кодомОригинал: Six of the Best Open Source Data Mining Tools
Автор: Chandan Goopta
Дата публикации: 9 октября 2014 года
Перевод: А. Кривошей
Дата перевода: май 2015 г.
Сегодня в мире происходит экспоненциальный рост количества данных. Однако эти данные, по большей части, неструктурированы, поэтому больших усилий требует процесс их обработки и извлечения полезной информации, а также преобразование ее в удобную для последующей работы форму. Здесь на сцену выходит data mining. Для решения задач обработки данных разработано большое количество инструментов, использующих элементы искусственного интеллекта, машинного обучения и других технологий обработки данных.
Ниже представлены шесть мощных программ с открытым исходным кодом для data mining:

Эта программа, написанная на Java, предлагает продвинутые возможности анализа данных, реализованные в виде основанного на шаблонах фреймвока. При этом пользователю вообще не требуется писать код. RapidMiner предлагается скорее в виде сервиса, а не отдельной программы, и занимает верхнюю позицию в нашем списке.
Кроме того, RapidMiner обеспечивает предварительную обработку и визуализацию данных, предиктивный анализ, статистическое моделирование. И наконец, он поддерживает учебные схемы, модели и алгоритмы из WEKA, а также скрипты на R.
RapidMiner распространяется под лицензией AGPL, и его можно скачать с SourceForge (бесплатно предлагается версия, которая на данный момент является предыдущей по отношению к коммерческой версии).
Изначально WEKA была разработана для анализа данных сельскохозяйственного сектора. Затем программа была переписана на Java и стала значительно сложнее. Теперь она используется в различных областях, включая визуализацию и алгоритмы для анализа данных и предиктивного моделирования. Она бесплатна и распространяется под лицензией GNU General Public License, что является большим плюсом по сравнению с RapidMiner, так как пользователи могут дорабатывать программу под свои нужды.
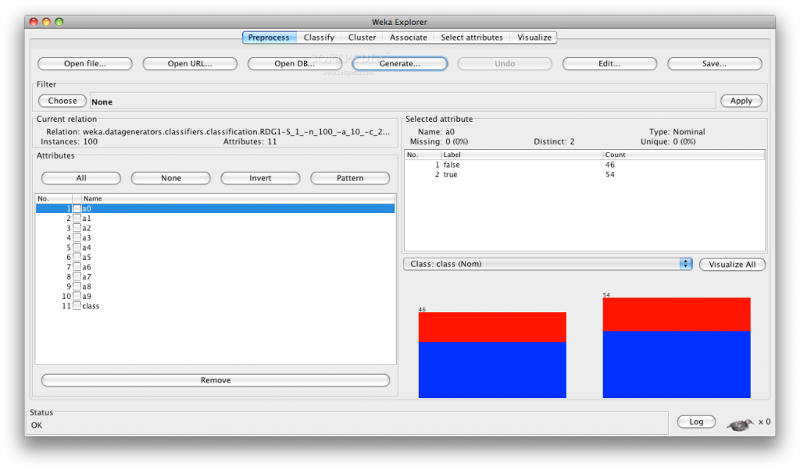
WEKA поддерживает ряд стандартных задач data mining, включая подготовку данных, визуализацию и выбор признаков.

R - это проект GNU, который изначально был написан на C и Fortran. Затем большое количество модулей было написано на самом R. Это свободный язык программирования и окружение для статистической обработки и визуализации данных. Язык R широко используется для разработки статистических программ и анализа данных. Простота использования и масштабируемость очень сильно повысили популярность R в последние годы.
Помимо задач data mining R хорошо подходит и для решения других близких задач, таких как линейная и нелинейная регрессия, классические статистические методы, анализ временных рядов и так далее.
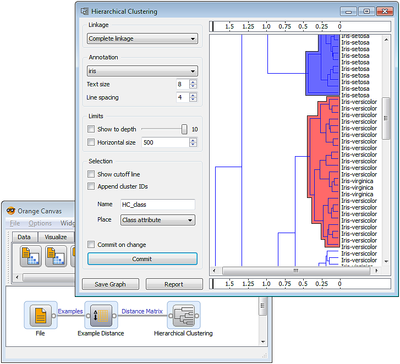
Python сейчас находится на пике популярности благодаря своей простоте и легкости изучения в сочетании с мощью. Поэтому, если вы ищете подходящий инструмент, и знаете Python, вам подойдет Orange - мощная утилита с открытым исходным кодом.
Вам понравится сочетание визуального программирования с написанием скриптов на Python. Также имеются компоненты для машинного обучения, биоинформатики и анализа текстов.
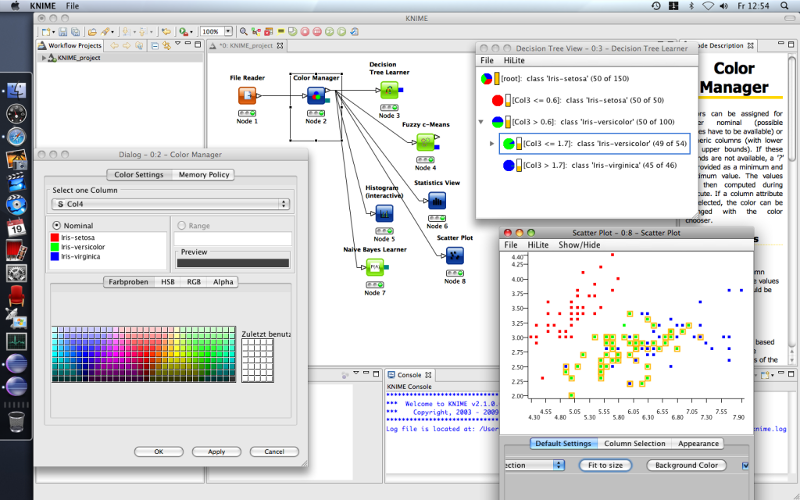
Подготовка данных включает три главных этапа: извлечение, преобразование и загрузку. KNIME обеспечивает выполнение всех трех. Он предлагает графический пользовательский интефейс, позволяющий конструировать процесс обработки данных. Это платформа с открытым исходным кодом для анализа данных и составления отчетов. В KNIME также интегрированы различные компоненты для машинного обучения и data mining, обеспечивающие совместно с концепцией построения конвейера из отдельных модулей возможности для бизнес-аналитики и анализа финансовых данных.
KNIME написан на Java и сделан на базе Eclipse, поэтому его возможности легко расширяются с помощью плагинов. Дополнительную функциональность можно добавить на лету. Множество модулей уже включено в базовую версию.
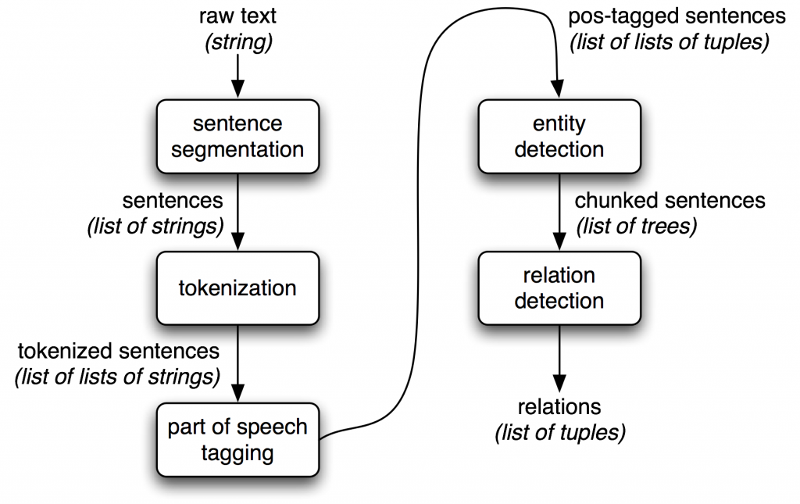
Если речь идет о задачах обработки естественного языка, ничто не сравнится с NLTK, который обеспечивает полный набор программного обеспечения для таких задач, включая data mining, машинное обучение, извлечение данных из веб-страниц, анализ тональности текста и другие задачи в области анализа языков. Поскольку NLTK написан на Python, вы можете включать его в свои приложения, подстраивая под свои задачи.
Эта статья еще не оценивалась
Вы сможете оценить статью и оставить комментарий, если войдете или зарегистрируетесь .
Только зарегистрированные пользователи могут оценивать и комментировать статьи.











Уже завтра состоится Data Fest?!
У нас будет идти онлайн-трансляция на youtube, а также мы дублируем ее на сайт datafest.ru и сайты яндекса.
Как вы уже знаете, инвайтов на всех не хватило. Ни мы, ни Яндекс не жадные до посадочных мест, однако нас достаточно много, и физической возможности пригласить всех желающих просто нет. Мы разослали 800 приглашений и немного волнуемся, не будет ли нам тесно. Если бы пригласили вообще всех желающих (а регистраций было в 2 раза больше), то вместить нас смог бы, наверное, только стадион
Data Fest? 10-11 Сентября
Яндекс и сообщество Open Data Science (opendatascience.ru ) запускают серию конференций «Data&Science», посвященную применению больших данных в фундаментальной и прикладной науке.
Первое мероприятие пройдет в московском офисе Яндекса 17 сентября, в субботу.
C 14:00 и до вечера будем говорить о физике высоких энергий, Большом адронном коллайдере и, конечно же, анализе данных.
Для тех, кто не сможет попасть на конференцию, мы организуем онлайн-трансляцию.
Подробности и регистрация: https://events.yandex.ru/events/ds/17-sept-2016/ .

Ссылка opendatascience.ru Блог http://opendatascience.ru


Привет, ребята!
Я всю жизнь занималась ИТ-рекрутментом, а потом мы придумали, как это дело можно умно автоматизировать.
И мне сейчас нужны несколько добровольцев для бета-теста нашего чатбота, круто умеющего находить и вести ИТ-шников)
Хотим помочь этим людям/командам нанять нужных спецов очень быстро и дешево (практически или полностью бесплатно, в зависимости от сложности), но попрсим фидбек для нас по сервису и юиксу. Показать полностью…
Приступаем на следующей неделе, поэтому лучше, чтобы команда сейчас активно пыталась нанять кого-то для девелопмента!
несколько моментов-пожеланий к таким людям:
1) сейчас машина умеет искать по всем источника девелоперов всех мастей, дата саентистов, и UX/UI дизайнеров.
2) нужен непосредственный hiring manager компании для взаимодействия (ПМ, СТО, нанимающий тимлид)
3) это не оч большая ИТ компания или стартап. Ни в коем случае не рекрутер или агенство, чтобы было меньше шагов от кандидата.
4) нанимающая команда использует для рабочей переписки Telegram или Slack мессенджеры на постоянной основе.
5) надо знать английский.
Пишите мне в лс в фб или на почту ai@xor.ai. я вышлю вам инвайт на установку в понедельник! :)

В предыдущей лекции мы кратко остановились на основных задачах Data Mining. Две из них - классификацию и кластеризацию - мы рассмотрим подробно в этой лекции.
Задача классификацииКлассификация является наиболее простой и одновременно наиболее часто решаемой задачей Data Mining. Ввиду распространенности задач классификации необходимо четкое понимания сути этого понятия.
Приведем несколько определений.
Классификация - системное распределение изучаемых предметов, явлений, процессов по родам, видам, типам, по каким-либо существенным признакам для удобства их исследования; группировка исходных понятий и расположение их в определенном порядке, отражающем степень этого сходства.
Классификация - упорядоченное по некоторому принципу множество объектов, которые имеют сходные классификационные признаки (одно или несколько свойств), выбранных для определения сходства или различия между этими объектами.
Классификация требует соблюдения следующих правил:
• в каждом акте деления необходимо применять только одно основание;
• деление должно быть соразмерным, т.е. общий объем видовых понятий должен равняться объему делимого родового понятия;
• члены деления должны взаимно исключать друг друга, их объемы не должны перекрещиваться;
• деление должно быть последовательным.
• вспомогательную (искусственную) классификацию, которая производится по внешнему признаку и служит для придания множеству предметов (процессов, явлений) нужного порядка;
• естественную классификацию, которая производится по существенным признакам, характеризующим внутреннюю общность предметов и явлений. Она является результатом и важным средством научного исследования, т.к. предполагает и закрепляет результаты изучения закономерностей классифицируемых объектов.
В зависимости от выбранных признаков, их сочетания и процедуры деления понятий классификация может быть:
• простой - деление родового понятия только по признаку и только один раз до раскрытия всех видов. Примером такой классификации является дихотомия, при которой членами деления бывают только два понятия, каждое из которых является противоречащим другому (т.е. соблюдается принцип: "А и не А");

• сложной - применяется для деления одного понятия по разным основаниям и синтеза таких простых делений в единое целое. Примером такой классификации является периодическая система химических элементов.
Под классификацией будем понимать отнесение объектов (наблюдений, событий) к одному из заранее известных классов.
Классификация - это закономерность, позволяющая делать вывод относительно определения характеристик конкретной группы. Таким образом, для проведения классификации должны присутствовать признаки, характеризующие группу, к которой принадлежит то или иное событие или объект (обычно при этом на основании анализа уже классифицированных событий формулируются некие правила).
Классификация относится к стратегии обучения с учителем (supervised learning), которое также именуют контролируемым или управляемым обучением.
Задачей классификации часто называют предсказание категориальной зависимой переменной (т.е. зависимой переменной, являющейся категорией) на основе выборки непрерывных и/или категориальных переменных.
Например, можно предсказать, кто из клиентов фирмы является потенциальным покупателем определенного товара, а кто - нет, кто воспользуется услугой фирмы, а кто - нет, и т.д. Этот тип задач относится к задачам бинарной классификации, в них зависимая переменная может принимать только два значения (например, да или нет, 0 или 1).
Другой вариант классификации возникает, если зависимая переменная может принимать значения из некоторого множества предопределенных классов. Например, когда необходимо предсказать, какую марку автомобиля захочет купить клиент. В этих случаях рассматривается множество классов для зависимой переменной.
Классификация может быть одномерной (по одному признаку) и многомерной (по двум и более признакам).
Многомерная классификация была разработана биологами при решении проблем дискриминации для классифицирования организмов. Одной из первых работ, посвященных этому направлению, считают работу Р. Фишера (1930 г.), в которой организмы разделялись на подвиды в зависимости от результатов измерений их физических параметров. Биология была и остается наиболее востребованной и удобной средой для разработки многомерных методов классификации.
Рассмотрим задачу классификации на простом примере. Допустим, имеется база данных о клиентах туристического агентства с информацией о возрасте и доходе за месяц. Есть рекламный материал двух видов: более дорогой и комфортный отдых и более дешевый, молодежный отдых. Соответственно, определены два класса клиентов: класс 1 и класс 2. База данных приведена в таблице 5.1 .
Таблица 5.1. База данных клиентов туристического агентства
Задача. Определить, к какому классу принадлежит новый клиент и какой из двух видов рекламных материалов ему стоит отсылать.
Для наглядности представим нашу базу данных в двухмерном измерении (возраст и доход), в виде множества объектов, принадлежащих классам 1 (оранжевая метка) и 2 (серая метка). На рис. 5.1 приведены объекты из двух классов.
Рис. 5.1. Множество объектов базы данных в двухмерном измерениии
Решение нашей задачи будет состоять в том, чтобы определить, к какому классу относится новый клиент, на рисунке обозначенный белой меткой.
Процесс классификацииЦель процесса классификации состоит в том, чтобы построить модель, которая использует прогнозирующие атрибуты в качестве входных параметров и получает значение зависимого атрибута. Процесс классификации заключается в разбиении множества объектов на классы по определенному критерию.
Классификатором называется некая сущность, определяющая, какому из предопределенных классов принадлежит объект по вектору признаков.
Для проведения классификации с помощью математических методов необходимо иметь формальное описание объекта, которым можно оперировать, используя математический аппарат классификации. Таким описанием в нашем случае выступает база данных.
Каждый объект (запись базы данных) несет информацию о некотором свойстве объекта.
Набор исходных данных (или выборку данных) разбивают на два множества: обучающее и тестовое.
Обучающее множество (training set) - множество, которое включает данные, использующиеся для обучения (конструирования) модели.
Такое множество содержит входные и выходные (целевые) значения примеров. Выходные значения предназначены для обучения модели.
Тестовое (test set) множество также содержит входные и выходные значения примеров. Здесь выходные значения используются для проверки работоспособности модели.
Процесс классификации состоит из двух этапов [21]: конструирования модели и ее использования.
1. Конструирование модели: описание множества предопределенных классов.
o Каждый пример набора данных относится к одному предопределенному классу.
o На этом этапе используется обучающее множество, на нем происходит конструирование модели.
o Полученная модель представлена классификационными правилами, деревом решений или математической формулой.
2. Использование модели: классификация новых или неизвестных значений.
o Оценка правильности (точности) модели.
1. Известные значения из тестового примера сравниваются с результатами использования полученной модели.
2. Уровень точности - процент правильно классифицированных примеров в тестовом множестве.
3. Тестовое множество, т.е. множество, на котором тестируется построенная модель, не должно зависеть от обучающего множества.
o Если точность модели допустима, возможно использование модели для классификации новых примеров, класс которых неизвестен.
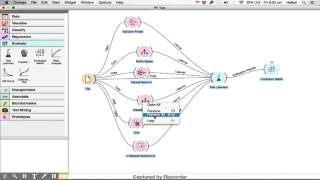
Процесс классификации, а именно, конструирование модели и ее использование, представлен на рис. 5.2. - 5.3 .

Рис. 5.6. Решение задачи классификации методом нейронных сетей
Точность классификации: оценка уровня ошибокОценка точности классификации может проводиться при помощи кросс-проверки. Кросспроверка (Cross-validation) - это процедура оценки точности классификации на данных из тестового множества, которое также называют кросс-проверочным множеством. Точность классификации тестового множества сравнивается с точностью классификации обучающего множества. Если классификация тестового множества дает приблизительно такие же результаты по точности, как и классификация обучающего множества, считается, что данная модель прошла кросс-проверку.
Разделение на обучающее и тестовое множества осуществляется путем деления выборки в определенной пропорции, например обучающее множество - две трети данных и тестовое - одна треть данных. Этот способ следует использовать для выборок с большим количеством примеров. Если же выборка имеет малые объемы, рекомендуется применять специальные методы, при использовании которых обучающая и тестовая выборки могут частично пересекаться.
Оценивание классификационных методовОценивание методов следует проводить, исходя из следующих характеристик [21]: скорость, робастность, интерпретируемость, надежность.
Скорость характеризует время, которое требуется на создание модели и ее использование.
Робастность. т.е. устойчивость к каким-либо нарушениям исходных предпосылок, означает возможность работы с зашумленными данными и пропущенными значениями в данных.
Интерпретируемость обеспечивает возможность понимания модели аналитиком.
Свойства классификационных правил:
• размер дерева решений;
• компактность классификационных правил.
Надежность методов классификации предусматривает возможность работы этих методов при наличии в наборе данных шумов и выбросов.
Задача кластеризацииТолько что мы изучили задачу классификации, относящуюся к стратегии "обучение с учителем".
В этой части лекции мы введем понятия кластеризации, кластера, кратко рассмотрим классы методов, с помощью которых решается задача кластеризации, некоторые моменты процесса кластеризации, а также разберем примеры применения кластерного анализа.
Задача кластеризации сходна с задачей классификации, является ее логическим продолжением, но ее отличие в том, что классы изучаемого набора данных заранее не предопределены.
Синонимами термина "кластеризация" являются "автоматическая классификация", "обучение без учителя" и "таксономия".
Кластеризация предназначена для разбиения совокупности объектов на однородные группы (кластеры или классы). Если данные выборки представить как точки в признаковом пространстве, то задача кластеризации сводится к определению "сгущений точек".
Цель кластеризации - поиск существующих структур.
Кластеризация является описательной процедурой, она не делает никаких статистических выводов, но дает возможность провести разведочный анализ и изучить "структуру данных".
Само понятие "кластер" определено неоднозначно: в каждом исследовании свои "кластеры". Переводится понятие кластер (cluster) как "скопление", "гроздь".
Кластер можно охарактеризовать как группу объектов, имеющих общие свойства.
Характеристиками кластера можно назвать два признака:
Вопрос, задаваемый аналитиками при решении многих задач, состоит в том, как организовать данные в наглядные структуры, т.е. развернуть таксономии.
Наибольшее применение кластеризация первоначально получила в таких науках как биология, антропология, психология. Для решения экономических задач кластеризация длительное время мало использовалась из-за специфики экономических данных и явлений.


Кластеры могут быть непересекающимися, или эксклюзивными (non-overlapping, exclusive), и пересекающимися (overlapping) [22]. Схематическое изображение непересекающихся и пересекающихся кластеров дано на рис. 5.8 .
Рис. 5.8. Непересекающиеся и пересекающиеся кластеры
Следует отметить, что в результате применения различных методов кластерного анализа могут быть получены кластеры различной формы. Например, возможны кластеры "цепочного" типа, когда кластеры представлены длинными "цепочками", кластеры удлиненной формы и т.д. а некоторые методы могут создавать кластеры произвольной формы.
Различные методы могут стремиться создавать кластеры определенных размеров (например, малых или крупных) либо предполагать в наборе данных наличие кластеров различного размера.
Некоторые методы кластерного анализа особенно чувствительны к шумам или выбросам, другие - менее.
В результате применения различных методов кластеризации могут быть получены неодинаковые результаты, это нормально и является особенностью работы того или иного алгоритма.
Данные особенности следует учитывать при выборе метода кластеризации.
Подробнее обо всех свойствах кластерного анализа будет рассказано в лекции, посвященной его методам.
На сегодняшний день разработано более сотни различных алгоритмов кластеризации. Некоторые, наиболее часто используемые, будут подробно описаны во втором разделе курса лекций.
Приведем краткую характеристику подходов к кластеризации [21].
• Алгоритмы, основанные на разделении данных (Partitioning algorithms), в т.ч. итеративные: o разделение объектов на k кластеров;
o итеративное перераспределение объектов для улучшения кластеризации.
• Иерархические алгоритмы (Hierarchy algorithms):
o агломерация: каждый объект первоначально является кластером, кластеры, соединяясь друг с другом, формируют больший кластер и т.д.
• Методы, основанные на концентрации объектов (Density-based methods):
Мы рассмотрели процесс Data Mining с двух сторон: как последовательность этапов и как последовательность работ. выполняемых исполнителями ролей Data Mining .
Существует еще одна сторона - это стандарты, описывающие методологию Data Mining. Последние рассматривают организацию процесса Data Mining и разработку Data Mining -систем.
CRISP-DM [100] (The Cross Industrie Standard Process for Data Mining - Стандартный межотраслевой процесс Data Mining ) является наиболее популярной и распространенной методологией. Членами консорциума CRISP-DM являются NCR, SPSS и DаimlerChrysler.
В соответствии со стандартом CRISP. Data Mining является непрерывным процессом со многими циклами и обратными связями .
Data Mining по стандарту CRISP-DM включает следующие фазы:
К этому набору фаз иногда добавляют седьмой шаг - Контроль. он заканчивает круг. Фазы Data Mining по стандарту CRISP-DM изображены на рис. 21.2 .

Рис. 21.2. Фазы, рекомендуемые моделью CRISP-DM
При помощи методологии CRISP-DM Data Mining превращается в бизнес-процесс. в ходе которого технология Data Mining фокусируется на решении конкретных проблем бизнеса. Методология CRISP-DM. которая разработана экспертами в индустрии Data Mining. представляет собой пошаговое руководство, где определены задачи и цели для каждого этапа процесса Data Mining .
Методология CRISP-DM описывается в терминах иерархического моделирования процесса [101], который состоит из набора задач, описанных четырьмя уровнями обобщения (от общих к специфическим): фазы, общие задачи, специализированные задачи и запросы.
На верхнем уровне процесс Data Mining организовывается в определенное количество фаз. на втором уровне каждая фаза разделяется на несколько общих задач. Задачи второго уровня называются общими, потому что они являются обозначением (планированием) достаточно широких задач, которые охватывают все возможные Data Mining -ситуации. Третий уровень является уровнем специализации задачи. т.е. тем местом, где действия общих задач переносятся на конкретные специфические ситуации. Четвертый уровень является отчетом по действиям, решениям и результатам фактического использования Data Mining .
CRISP-DM - это не единственный стандарт, описывающий методологию Data Mining. Помимо него, можно применять такие известные методологии, являющиеся мировыми стандартами, как Two Crows, SEMMA. а также методологии организации или свои собственные.
Программа помогает получить базовые компетенции аналитика данных, среди которых адекватный выбор метода для решения конкретной задачи анализа данных, предобработка данных, настройка параметров метода анализа и интерпретация полученных результатов. В ходе обучения слушатели также знакомятся с программными продуктами Weka, Orange и библиотекой scikit-learn. Содержание программы охватывает основные устоявшиеся разделы современного машинного обучения (Machine Learning) и майнинга данных (Data Mining).
Теоретический материал подкрепляется большим количеством практических занятий.
Итоговая аттестация будет проводиться в форме защиты проекта по анализу реальных данных.
ПреподавателиДмитрии? Игнатов
Кандидат технических наук, преподаватель факультета компьютерных наук НИУ ВШЭ, доцент Департамента анализа данных и искусственного интеллекта, научныи? сотрудник Международнои? научно-учебнои? лаборатории интеллектуальных систем и структурного анализа. Проходил обучение по PhD программе в Техническом университете Дрездена (Германия) в рамках гранта DAAD.
Юрии? Кашницкии?
Выпускник МФТИ, научный сотрудник и аспирант НИУ ВШЭ. Преподаватель языка Python и машинного обучения на факультете компьютерных наук НИУ ВШЭ. Имеет публикации на семинарах топовых конференции? по искусственному интеллекту (IJCAI и ECAI) и машинному обучению (ECML/PKDD). Ранее — Hadoop-разработчик, бизнес-аналитик и Java-программист РДТЕХ.
Вячеслав Дубров
Кандидат технических наук, аналитик больших массивов данных в IQmen - Business Intelligence. Проходил обучение по PhD программе в Техническом университете Ильменау (Германия) в рамках гранта DAAD и научные стажировки в ТУ Брауншвайг и ТУ Дортмунд. Ранее — разработчик систем машинного обучения в сфере сетевой безопасности (ЗАО "Перспективный мониторинг") и младший научный сотрудник ЮРГПУ(НПИ) имени М.И.Платова
Знание базовой программы курса «Высшая математика» и основ программирования (желательно Python). Для тех, кто еще не знаком с основами программирования, но хочет узнать об инструментах машинного обучения и майнинга данных, мы разработали программу "Введение в машинное обучение и майнинг данных" .
Начало занятии?3 ноября. Занятия будут проходить по вторникам и четвергам
Обучение современным методам анализа данных невозможно без применения специализированных программных средств и выполнения практических заданий, но возможно ли создание такого лабораторного практикума без использования коммерческого ПО? Образовательный проект кафедры анализа данных и искусственного интеллекта ГУ-ВШЭ призван ответить на этот вопрос.

Специалист, не только владеющий теоретическими знаниями, но и умеющий решать различные задачи анализа с помощью специализированного программного обеспечения, более востребован, поэтому курс, разработанный на кафедре анализа данных и искусственного интеллекта, прежде всего ориентирован на практическое применение современных методов разработки (добычи) данных на реальных массивах, причем с помощью свободно распространяемых программных инструментов. Во внимание были приняты многочисленные просьбы со стороны коллег и студентов факультета бизнес-информатики и отделения прикладной математики, и в курс были включены лекции и практические занятия по современным аналитическим пакетам.
Практикум можно пополнять; например, в будущем в него планируется включить лабораторные работы, связанные со специальными видами данных: категоризация текстов, анализ графовых структур и т.п. Часть лабораторных работ практикума подготовлена научно-учебной группой "Рекомендательные интернет-сервисы и интеллектуальный анализ данных" факультета бизнес-информатики ГУ-ВШЭ.
Методика обученияКвалифицированный аналитик должен уметь самостоятельно провести необходимую работу с данными, определить тип задачи (классификация, кластеризация, прогнозирование, поиск зависимостей и т.п.), решить ее адекватно выбранным методом с оптимально определенными параметрами, оценить результаты, сделать содержательные выводы и интерпретировать. Кроме обучения таких специалистов практикум должен способствовать формированию культуры оформления аналитических отчетов и освоению поискового и проблемно-ориентированного подхода к решению задач анализа данных.
Студент изучает необходимый теоретический минимум, изложенный в описании работы, отвечает на вопросы для проверки готовности к выполнению лабораторной работы, получает данные, использует программное обеспечение, выбирает подходящую модель и метод, пытается решить задачу. Результаты работы метода могут быть как удовлетворительными, например метод успешно решает задачу прогнозирования для 92% тестовой выборки, или нет, например когда количество правильных предсказаний низко - 28%. Возникает вопрос, почему задача не решена. Причиной низкого качества предсказаний могут быть: неправильная спецификация модели, шумы и ошибки в данных, неадекватный выбор метода анализа данных и/или его параметров, некорректный способ оценки качества предсказаний и т.п. Как и в случае с научными гипотезами, необходимо подвергать сомнению правильность действий аналитика на каждом из этапов работы и предлагать шаги по улучшению схемы анализа данных. Принципы, лежащие в основе научных гипотез, как нельзя лучше согласуются с понятием схемы анализа данных: проверяемость, максимальная общность, предсказательная сила и простота.
Немаловажным аспектом обучения анализу данных является формирование умения интерпретировать полученные результаты, например объяснять причинно-следственные связи на основе найденных закономерностей (поиск ассоциативных правил). Следует также отметить дифференцированный характер такого подхода к обучению, так как студент в рамках лабораторной работы решает задачу индивидуально, отвечая на вопросы преподавателя по конкретной теме работы.
При таком построении курса устраняется разрыв между знанием теории метода и его использованием на реальных данных. От преподавателя требуется контролировать выполнение студентами лабораторных работ практикума, проверять знания студентов после изучения материала теоретического минимума, проверять итоговые отчеты, консультировать студента. Для полноценного проведения практикума преподаватель должен быть знаком с применяемыми программными системами и владеть математическими моделями и алгоритмами, лежащими в основе методов анализа данных этого курса.
Предполагаемое количество часов курса рассчитывается исходя из выбранного для проведения числа лабораторных работ. Примерно 2-4 академических часа отводится на выполнение одной лабораторной работы и столько же на защиту всех работ. Оптимальное количество студентов в компьютерном классе - 15-20 человек на одного преподавателя.
В учебном плане бакалавриата четвертого курса на 2010/11 учебный год отделения прикладной математики и информатики курс называется "Системы разработки данных и машинного обучения", на него отводится 22 лекционных часа и 24 часа практических занятий, а в качестве форм контроля указана одна контрольная работа и зачет по итогам практикума.
Перед выполнением лабораторной работы студент отвечает на вопросы и выполняет задания для допуска к практикуму (простые модельные расчеты, производимые вручную). Здесь оценивается уровень понимания студентом выбранной модели или метода, правильность сделанных вручную расчетов для учебного примера. После выполнения работы оценивается соблюдение формальных требований к отчету, правильность выполнения работы (обработка данных, спецификация модели, оценка качества результатов и т.п.), верность и значимость выводов, приемлемость предлагаемой интерпретации результатов. Далее преподаватель проверяет знания студентов по материалам предоставленных ими отчетов с учетом замечаний и ошибок, выявленных ранее.
Студенты получают в качестве задания одну из списка лабораторных работ, текст этой работы в электронном виде или на бумажном носителе. Далее, следуя инструкции по выполнению лабораторной работы, студент отвечает на вопросы теоретического минимума и для предложенного набора данных проводит исследование по шагам, фиксируя результаты в электронной форме отчета.
Содержание курса и программные системы анализа данныхЛабораторные работы проводятся по следующим темам:
С одной стороны, все это наиболее востребованные на практике методы, а с другой - cреди них есть алгебраические методы, которые успели завоевать популярность в научных кругах для решения задач разработки данных и машинного обучения, но еще не так хорошо известны рядовым аналитикам.
Вопросы для допуска к лабораторной работе могут включать дополнительные задания в виде модельных учебных расчетов, выполняемых вручную для наборов данных размерами семь-десять объектов на пять-шесть признаков для различных предметных областей (выдача кредита, предсказание угона автомобиля, определение съедобности грибов, выбор партнера для знакомства и т.п.). Такой подход позволяет привлечь и сконцентрировать внимание учащегося на сути метода и разобрать его работу в подробностях.
В качестве инструментов исследования предполагается использовать свободное ПО для добычи данных (data mining) и машинного обучения. Действительно, использование только промышленного программного обеспечения не позволяет сделать курс доступным для изучения в течение одного-двух учебных модулей - этому препятствует сложность установки и настройки программного обеспечения (Microsoft SQL Server, Oracle Data Miner и т.д.). Кроме того, сложность промышленных технологий для обработки больших объемов данных может скрыть суть изучаемых методов анализа данных. Коммерческие аналитические пакеты часто содержат излишнюю функциональность, так как ориентированы на использование статистических методов (Statistica, Stata, SPSS и т.п.), а данный курс сосредоточен на методах data mining и машинного обучения. Бесплатно распространяемые программные системы для анализа данных позволяют избежать указанных сложностей - обычно они создаются учеными-практиками в ведущих лабораториях и потому часто обладают наиболее актуальной на сегодняшний день функциональностью.
В лабораторных работах курса используются следующие открытые программные системы: Weka 3 - Data Mining Software in Java (разработана командой специалистов Университета Вайкато, Новая Зеландия); Orange - Data Mining Fruitful & Fun (пакет создан лабораторией искусственного интеллекта Университета Любляни, Словения); QuDA - Data Miner Discovery Environment (разработана в техническом Университете города Дармштадта, Германия); Coron System - платформа добычи данных (разработана коллегами из группы Orpailleur в лаборатории LORIA Университета Нанси, Франция); Concept Explorer - один из основных инструментов анализа формальных понятий (разработан в Техническом университете Дармштадта, Германия); RSES2 - Rough Set Exploration System (разработана в Институте математики Университета Варшавы, Польша). Каждая программная система используется как минимум в одной лабораторной работе, а все перечисленные средства могут работать под управлением большинства современных ОС.
Другая проблема для такого курса - нехватка реальных данных, поэтому предлагается использовать репозитории, сформированные научным сообществом, в частности UCI Machine Learning Repository, созданный для нужд исследователей в области машинного обучения в Калифорнийском университете Ирвина и содержащий 190 наборов данных по разным областям физики, техники, биологии, медицины, социологии, бизнеса и др. Другой тип репозиториев характерен для соревнований в рамках конференций по анализу данных, например, Frequent Itemset Mining Implementations Repository, в котором помимо данных содержатся исходные коды алгоритмов. Хранимые в них наборы данных получены при решении реальных задач, многие из которых представляют собой актуальную научно-практическую проблему - ученые применяют эти наборы данных для доказательства качества и пригодности предложенных ими новых методов анализа данных.
Все программы, а также наборы данных и тексты лабораторных работ доступны в электронном виде, в том числе на сайте факультета. Возможность выполнять практикум вне аудиторных условий делает его пригодным для самостоятельной работы в рамках тех курсов, где аудиторное число часов ограничено или нет возможности использовать компьютерное оборудование.
Предварительные требования к знаниям, умениям и навыкам студентовСтуденты должны владеть основными понятиями из курса дискретной математики: множество, отображение, бинарное отношение, свойства бинарных отношений, частичный порядок, диаграмма частичного порядка, функция, исчисление высказываний и предикатов первого порядка, граф и алгоритм. Знания из курса линейной алгебры включают вычисления с матрицами, нахождение собственных чисел и собственных векторов, решение матричных уравнений. Знания из курса теории вероятностей предполагают предварительное знакомство студентов с понятием вероятности, алгеброй событий, независимости событий и теоремой Байеса. Дополнительным требованием является знакомство с понятием информационной энтропии Шеннона.
Несмотря на появление учебной литературы по методам машинного обучения и добычи данных, предлагаемый лабораторный практикум уникален на российском образовательном рынке в силу открытости используемого ПО, предоставляемого ведущими международными научно-исследовательскими коллективами, и ориентацией именно на выработку умений по его применению в учебных и реальных задачах.
Дмитрий Игнатов (dignatov@hse.ru) - преподаватель кафедры анализа данных и искусственного интеллекта, ГУ-ВШЭ (Москва).
Знания, умения и навыки
Основные знания, необходимые для свободного выполнения практикума, получены студентом в рамках лекций соответствующих курсов, тем не менее для каждой лабораторной работы приводится необходимый теоретический минимум. В перечень основных знаний, активно использующихся в курсе, входят:
Студенты должны обладать навыками установки и настройки свободного ПО для анализа данных (Concept Explorer, Coron, Orange, Weka, QuDA, RSES2 и т.д.); загрузки учебных и исследовательских наборов данных из открытых репозиториев, например UCI и FIMI и т.п.; работы с наборами данных и программным обеспечением. Особое внимание уделяется таким аспектам, как: умение выбрать метод анализа данных в соответствии с поставленной целью, характером задачи и данных; понимание математических моделей, лежащих в основе методов, описанных в базовых терминах теории множеств, упорядоченных структур, прикладной алгебры и т.п.; способность студента сформулировать и выполнить простые модельные расчеты, поясняющие суть конкретного метода; написание учебных (аналитических) отчетов, представляющих собой мини-исследование по применению конкретной модели, метода и данных, с результатами экспериментов, промежуточными отчетами и выводами (фактически протокол выполнения лабораторной работы); поисковые умения, направленные на исследование актуальной проблемы или задачи, которые активно обсуждаются научным сообществом; чтение дополнительной научной и учебной литературы, в том числе на английском языке, изучение нового ПО (не описанного в текстах практикума); умение правильно интерпретировать полученные результаты.
Пример расчетного задания для задачи классификации: угоняемость автомобилей
Требуется предсказать факт угона, и, как видно в этом случае, без предварительного шкалирования справиться с задачей сложно. Если решать эту задачу с помощью ДСМ-метода (метод назван в честь английского философа Джона Стюарта Милля и основан на обучении гипотезам по положительным и отрицательным примерам явления с помощью операции сходства), то можно получить несколько гипотез в пользу положительной (угоняют) и отрицательной (не угоняют) классификации объектов. Положительные: <красный, спортивный>, <желтый, Япония, нет повреждений> и <спортивный, Япония>. Отрицательные: <желтый, США> и <красный, джип, Япония, есть повреждения>. Согласно найденным гипотезам примеры 8, 9 и 10 классифицируются соответственно отрицательно, положительно и неопределенно. Подобные задачи студент решает, выполняя вычисления вручную во время сдачи допуска к лабораторной работе.
Различные методы обладают своими особенностями, например, ДСМ-метод строит прогнозы очень осторожно, что делает его полезным, например, в задачах прогнозирования токсичности веществ - меньше ошибка отнесения ядовитых веществ к нетоксичным. Задачи для вычислений с помощью программных систем проводятся на более крупных наборах данных: когда ясна суть метода, очень важно научить аналитиков умению интерпретировать результаты, среди которых может оказаться не так много новых нетривиальных знаний.
Предлагать наборы данных более крупных размеров, содержащие несколько миллионов объектов или признаков, не входит в задачи курса, так как для успешного овладения методами снижения размерности и отбора релевантных ("интересных") объектов или признаков достаточно исследования массивов размерами порядка 1 тыс. объектов на 100 признаков.